Chapter 6 选题指南
项目可分为指南任务和自由选题两部分。
- 部分指南任务的描述较为详细,一部分仅为一个题目。具体的实施方案请思考并与本研究组沟通。
- 自由选题方向请注意:仅限大气、水文、地理、遥感、生态方向,以及与以上方向有交叉的计算机、高性能计算、人工智能、软硬件设备等。项目中请优先使用SHUD模型。 恕能力限制,其他方向无法提供学术指导和经费支持。
任务分为两类:
- 以R 开头的项目属于研究性任务,需要发表研究论文方能结题。
- 以D开头的项目是应用实践性任务,主要涉及数据处理、设备研发和程序开发,主要的成果形式是软著和专利。
6.2 指南任务列表
以下为指南任务,我们主要提供一个研究的主题或者思路,由申请者来寻找具体的路径去实现,实现的方法非常灵活。
6.2.1 研究类任务
6.2.1.1 R1. Rum River水文模拟
Rum River是美国密西西比河上游区域的一个子流域。该流域面积约4000平方公里,上游存在一个大湖。
路径:
- 利用1979-2023年的小时尺度NLDAS数据和SHUD模型对Rum River的径流进行模拟。
- 模拟结果要求可靠的(多个水文站)径流、地下水空间分布和时间变化。
- 分析和总结Rum River的各个子流域的地理特征(坡度、坡向等)。
- 初步使用LSTM和GraphNET等深度学习方法进行子流域径流模拟。
难点:
- 时间序列较长。
- 需要收集NWIS发布的各水文数据。
- 需要有较好的英文基础,与美国的合作者定期(每周一次)组会。
技能要求:
- 具有较强的英文听说读写能力。
- 能够快速使用R语言。
- 懂地理和水文数据。
- 能运行简单的深度学习模型。
6.2.1.2 R2. 区域历史径流再分析资料生成
针对特定的流域,使用SHUD模型和再分析气象资料,进行长期径流模拟。
路径:
- 构建流域SHUD模型。
- 使用径流、地下水、蒸发等数据对模型进行校准和验证。
- 开展长时间序列数据模拟。
- 分析长期水文演变特征。
6.2.1.3 R3. SHUD模型在湿地研究中的应用
利用SHUD模型进行湿地面积、储水量、水源涵养功能方面的评价和应用研究。
路径:
- 选择代表性湿地作为研究区域。
- 通过径流、地下水、和蒸发数据对SHUD模型模拟效果进行验证。
- 分析区域湿地的形成因素和长时间序列下湿地的变化特征。
- 解析湿地变化特征下的各水文要素的影响。
难点:
- SHUD模型的构建和建模。
- 模型调参的过程和数据准备。
技能要求:
- 会使用R,Python之一。
- 能够读懂C/C++代码,能够进行debug。
6.2.1.4 R4. 黑河流域地表-地下水交互过程的模拟研究
使用SHUD模型对祁连山黑河流域的地表地下水交互过程进行研究。
路径: 1. 构建黑河流域SHUD模型。 2. 使用径流和地下水位进行调参。 3. 分析中下游地表地下水的交互过程。
难点:
- SHUD模型的构建和建模。
- 模型调参的过程和数据准备。
- 黑河中下游地下水位观测点数据获取。
6.2.1.5 R5. SHUD在无观测流域中的应用。
在物理模型中,水文模拟的主要障碍是参数的不确定性。在理论上,当参数不确定性消失,那么,物理模型应当是“防止四海皆准”而不需要处处分别校准。
路径:
- 测试SHUD模型的参数敏感性。
- 利用全球公开的流域径流数据,开展SHUD模型的校准。
- 寻找多流域参数公约数。
- 参数移植至无观测流域的检验。
难点:
- 流域选择非常多。
- 多个流域的模型的快速构建。
- 模型校准耗时。
- 结果不确定性大。
技能要求:
- 会使用R,Python之一。
- 能够读懂C/C++代码,能够进行debug。
- 有充足的水文和地理学背景。
- 有强大的逻辑分析能力。
6.2.1.6 R6. SHUD模型在山洪预报中的应用
使用山洪对历史多次山洪事件进行模拟和重现。
路径:
- 搜集近年来的山洪事件,筛选可用于研究的山洪事件。
- 使用AutoSHUD,快速构建SHUD模型。
- 利用可用数据对各次山洪数据进行模拟。
- 对SHUD模型在山洪模拟中的作用和价值做出评估。
难点:
- 山洪往往发生在无观测区域,没有可靠的验证数据。
- 降雨数据是山洪模拟的关键信息。
技能要求:
- 能读懂多普勒雷达降雨图,知道单位如何转换。
- 能够快速使用R语言。
- 对山洪和洪水有理解。
6.2.1.7 R7. 历史气候资料降尺度
利用百年尺度的历史气候资料,对南美危地马拉Tikal国家公园的区域进行气候降尺度数据生成。
路径:
- 收集公元700-1200年间Tikal国家公园的气候资料。
- 利用不同的降尺度方法生成降尺度数据。
- 对降尺度数据进行评估。
难点:
- 降尺度数据的可靠性。
- 对于历史气候数据进行降尺度,不确定性高。
技能要求:
- 会使用降尺度方法。
- 能够快速搜索多学科文献。
- 具有古气候变化的基本研究背景。
6.2.1.8 R8. SHUD模型最优分辨率问题,网格无关性问题
需要回答在不同的流域径流模拟中,最优的空间分辨率是什么?
问题
- 不同流域的最优分辨率是多少?
- 是否存在网格无关性(mesh independance)?
6.2.1.10 R10. 评价模型的GOF的正确认识?
各种拟合优度函数(GOF,goodness of fitting)自身是否存在局限性和倾向性?对模拟结果评价时,如何选取合适合理的GOF函数?
技能要求:
- 较好的统计基础理论。
- 熟练使用R或Python。
6.2.2 实践和开发类任务
6.2.2.1 D1. SHUD模型中NetCDF输入输出模块
给SHUD模型加入支持读取NetCDF格式气象数据的模块。
当前SHUD模型的驱动数据制备如下图所示,需要NetCDF预处理程序,读取时间序列数据并生成可读的数据文件,然后驱动SHUD模型进行模拟。
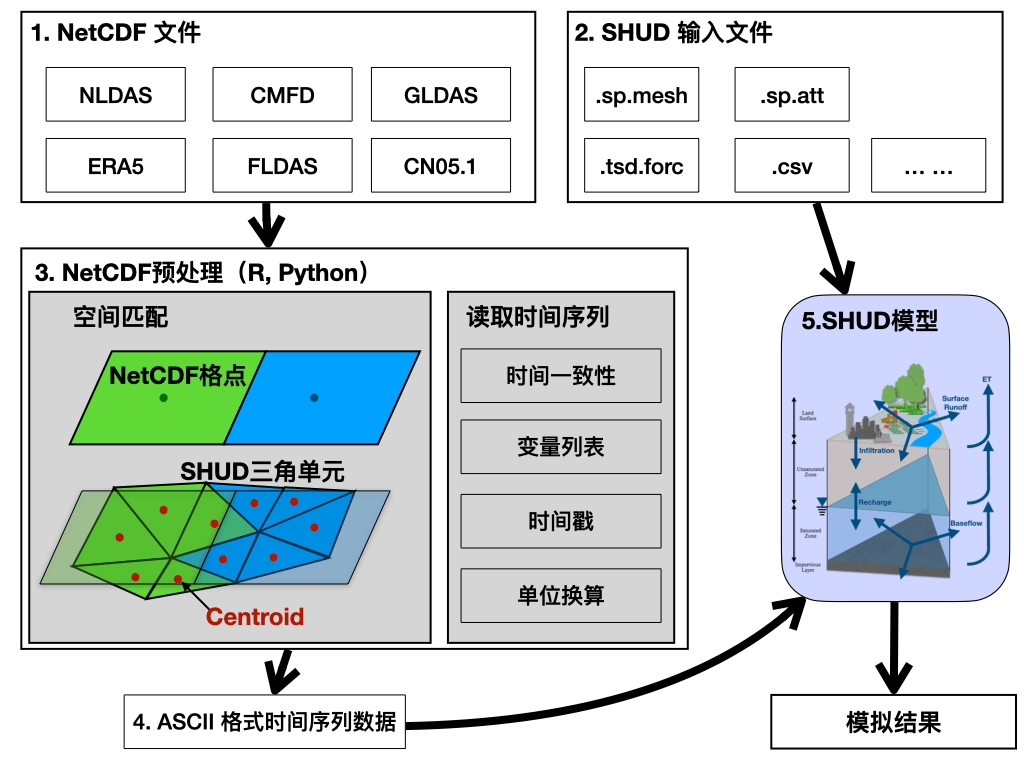
本任务的目标是实现以下的方式:
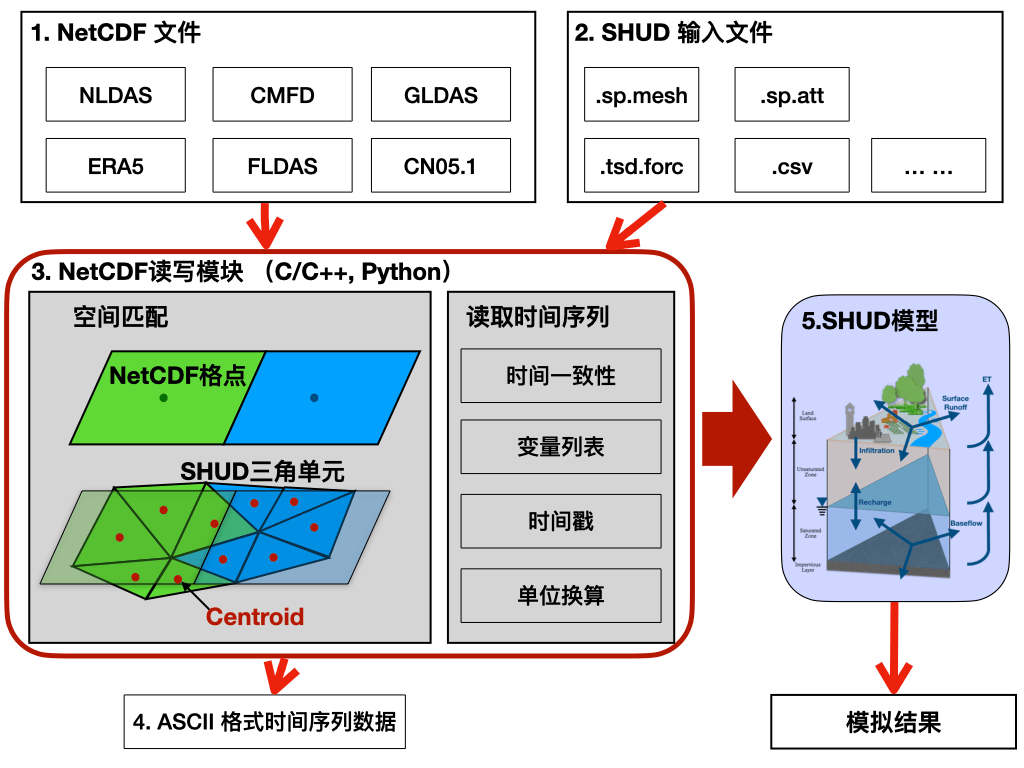
技能要求:
- 懂C/C++
- 能快速了解NetCDF数据结构。
- 了解GIS和空间数据。
6.2.2.2 D2. 生产全国水文模拟系统的输入数据
我们已开发了全国水文模拟系统(https://nwm.ac.cn),但是这个系统中数据需要改进以提高计算效率和计算一致性。这一工作的路径非常清晰,但需要较多耐心去完成。
路径:
- 系统性检查Shapefile河道数据。
- 对河道数据进行适度简化。
- 以全国流域片区对数据进行分解。
- 建立流域片区的SHUD模型输入文件。
技能要求:
- 懂GIS软件。
- 会空间数据分析。
*注:推荐有GIS经验的同学申请。
6.2.2.3 D2. 全球水文云计算平台中多模型集成任务
GHDC(https://ghdc.ac.cn)网站可以为用户提供自动化的全球水文建模数据获取和水文建模任务,但是现在这个平台仅支持SHUD模型的自动化建模。因此本任务需要在当前网站数据流程框架下,开发其他模型支持模块,例如SWAT, TOPMODEL, 等等。
技能要求:
- 精通Python, R之一。
- 懂水文建模,至少初步经验。
6.2.2.4 D3. 全球水文云计算平台中API测试和改进任务
GHDC(https://ghdc.ac.cn)网站可以为用户提供自动化的全球水文建模数据获取和水文建模任务。
GHDC服务支持网页和API方式提交数据,但是API模块仍然需要诸多的测试和改进。
技能要求:
- 精通Python。
- 会用R。
- 会前台网页服务。
*注:此任务有专业老师指导完成。