Chapter 2 数值方法基础
2.1 隐式与显式求解法
数值方法可分为显式求解(Explicit method)与隐式求解(Implicit method):
Definition 2.1 (显式求解法) 当下一时刻变量由前一时刻变量直接计算得到的,称为显式求解法。数学表达可写为:
Definition 2.2 (隐式求解法) 当下一时刻变量由一系列公式、矩阵或者迭代算法计算得到,称为隐式求解法。数学表达可写为:
相同时空分辨率条件下,显式求解法的计算速度显著高于隐式求解法,但是隐式求解法可以保证计算的稳定性,因此可采用较大时间步长进行计算,而显式求解法必须受制于CFL条件。
2.2 数值迭代方法
2.2.1 牛顿迭代(Newton Iteration)
牛顿迭代法(Newton’s method)又称为牛顿-拉夫逊(拉弗森)方法(Newton-Raphson method),是一种在实数域和复数域上近似求解方程的方法。方法使用函数 的泰勒级数的前面几项来寻找方程的根。
2.2.2 欧拉方法(Euler Method)
在数学和计算机科学中,欧拉方法,命名自它的发明者萊昂哈德·歐拉,是一种一阶数值方法,用以对给定初值的常微分方程(即初值問題)求解。它是常微分方程數值方法中最基本的显式方法(Explicit method)。 欧拉方法是一个一阶方法,意味着其局部截断误差(每步误差)正比于步长的平方,并且其全局截断误差正比于步长。欧拉方法经常应用于作为构建一些更复杂方法的基础,例如,预估-校正方法。
Definition 2.3 (欧拉方法) 欧拉方法数学表达为: 求解时: 其中,即迭代步长, 。 欧拉方法属于显式求解法。
Example 2.1 已知函数: 求:
# source: https://en.wikipedia.org/wiki/Euler_method
# ============
# SOLUTION to
# y' = y, where y' = f(t,y)
# then:
f <- function(ti,y) y
# INITIAL VALUES:
t0 <- 0
y0 <- 1
h <- .1
tn <- 4
# Euler's method: function definition
Euler <- function(t0, y0, h, tn, dy.dt) {
# dy.dt: derivative function
# t sequence:
tt <- seq(t0, tn, by=h)
# table with as many rows as tt elements:
tbl <- data.frame(ti=tt)
tbl$yi <- y0 # Initializes yi with y0
tbl$Dy.dt[1] <- dy.dt(tbl$ti[1],y0) # derivative
for (i in 2:nrow(tbl)) {
tbl$yi[i] <- tbl$yi[i-1] + h*tbl$Dy.dt[i-1]
# For next iteration:
tbl$Dy.dt[i] <- dy.dt(tbl$ti[i],tbl$yi[i])
}
return(tbl)
}
# Euler's method: function application
r <- Euler(t0, y0, h, tn, f)
rownames(r) <- 0:(nrow(r)-1) # to coincide with index n
# Exact solution for this case: y = exp(t)
# added as an additional column to r
r$y <- exp(r$ti)
plot(r$ti, r$y, type="l", col="red", lwd=2)
lines(r$ti, r$yi, col="blue", lwd=2)
grid(col="black")
legend("top", legend = c("Exact", "Euler"), lwd=2, col = c("red", "blue"))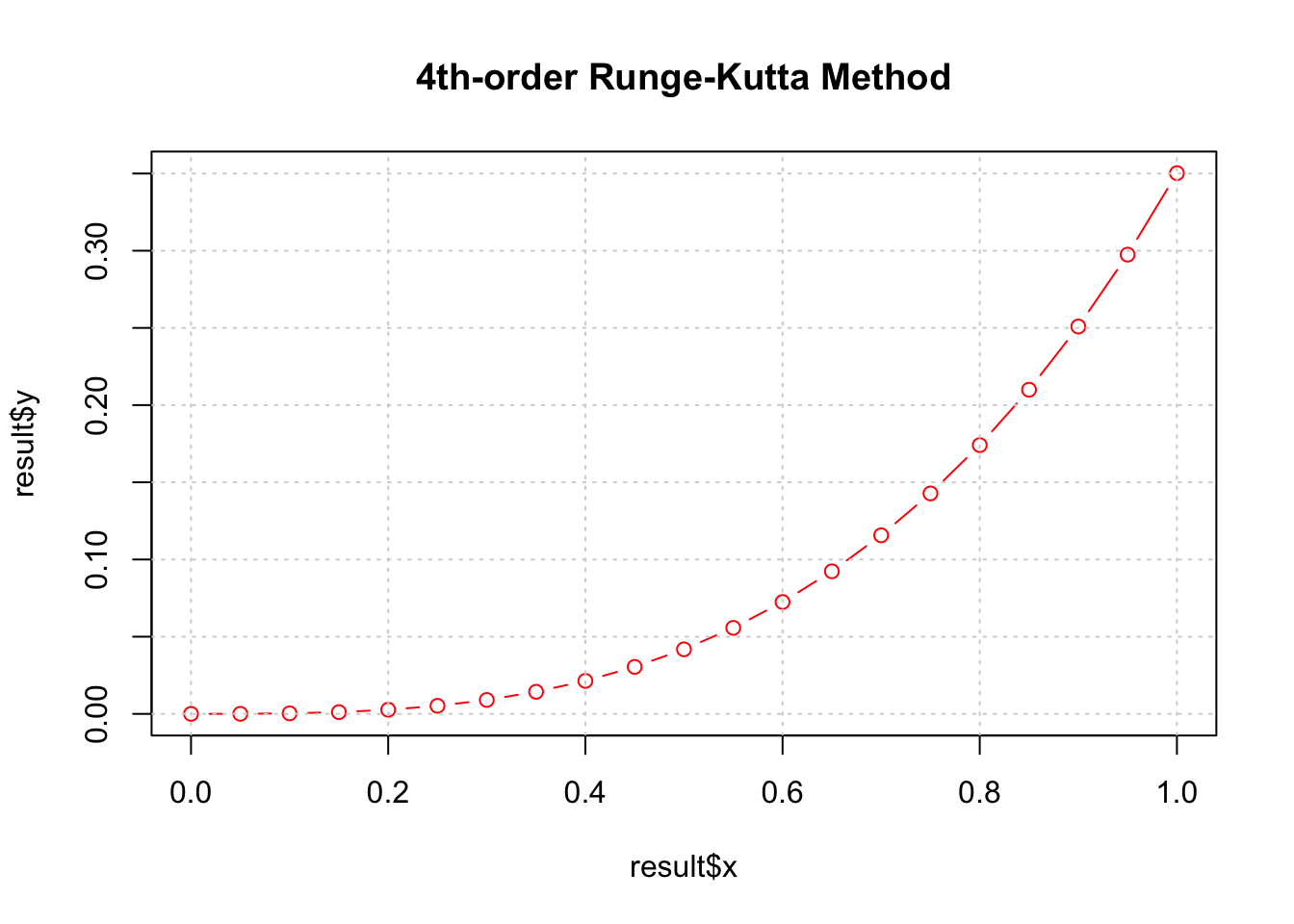
## ti yi Dy.dt y
## 0 0.0 1.000000 1.000000 1.000000
## 1 0.1 1.100000 1.100000 1.105171
## 2 0.2 1.210000 1.210000 1.221403
## 3 0.3 1.331000 1.331000 1.349859
## 4 0.4 1.464100 1.464100 1.491825
## 5 0.5 1.610510 1.610510 1.648721
## 6 0.6 1.771561 1.771561 1.822119
## 7 0.7 1.948717 1.948717 2.013753
## 8 0.8 2.143589 2.143589 2.225541
## 9 0.9 2.357948 2.357948 2.459603
## 10 1.0 2.593742 2.593742 2.718282
## 11 1.1 2.853117 2.853117 3.004166
## 12 1.2 3.138428 3.138428 3.320117
## 13 1.3 3.452271 3.452271 3.669297
## 14 1.4 3.797498 3.797498 4.055200
## 15 1.5 4.177248 4.177248 4.481689
## 16 1.6 4.594973 4.594973 4.953032
## 17 1.7 5.054470 5.054470 5.473947
## 18 1.8 5.559917 5.559917 6.049647
## 19 1.9 6.115909 6.115909 6.685894
## 20 2.0 6.727500 6.727500 7.389056
## 21 2.1 7.400250 7.400250 8.166170
## 22 2.2 8.140275 8.140275 9.025013
## 23 2.3 8.954302 8.954302 9.974182
## 24 2.4 9.849733 9.849733 11.023176
## 25 2.5 10.834706 10.834706 12.182494
## 26 2.6 11.918177 11.918177 13.463738
## 27 2.7 13.109994 13.109994 14.879732
## 28 2.8 14.420994 14.420994 16.444647
## 29 2.9 15.863093 15.863093 18.174145
## 30 3.0 17.449402 17.449402 20.085537
## 31 3.1 19.194342 19.194342 22.197951
## 32 3.2 21.113777 21.113777 24.532530
## 33 3.3 23.225154 23.225154 27.112639
## 34 3.4 25.547670 25.547670 29.964100
## 35 3.5 28.102437 28.102437 33.115452
## 36 3.6 30.912681 30.912681 36.598234
## 37 3.7 34.003949 34.003949 40.447304
## 38 3.8 37.404343 37.404343 44.701184
## 39 3.9 41.144778 41.144778 49.402449
## 40 4.0 45.259256 45.259256 54.5981502.2.3 龙格-库塔方法(Runge-Kutta Method)
数值分析中,龙格-库塔方法(Runge-Kutta Methods)是用于非线性常微分方程的解的重要的一类隐式或显式迭代法。这些技术由数学家卡尔·龙格和马丁·威尔海姆·库塔于1900年左右发明。
这里介绍最常见的四阶龙格-库塔方法。
Definition 2.4 (龙格-库塔方法) 龙格-库塔方法求解过程为: 即迭代步长, 。
实现四阶龙格-库塔算法的R代码:
# Define the derivative function
dydx <- function(x, y) {
return(x^2 + y^2)
}
# Define the Runge-Kutta method
rk4 <- function(y0, x0, h, n) {
# Initialize arrays
x <- rep(0, n+1)
y <- rep(0, n+1)
# Set initial values
x[1] <- x0
y[1] <- y0
# Iterate over n steps
for (i in 1:n) {
k1 <- h * dydx(x[i], y[i])
k2 <- h * dydx(x[i] + h/2, y[i] + k1/2)
k3 <- h * dydx(x[i] + h/2, y[i] + k2/2)
k4 <- h * dydx(x[i] + h, y[i] + k3)
y[i+1] <- y[i] + (k1 + 2*k2 + 2*k3 + k4) / 6
x[i+1] <- x[i] + h
}
# Return the arrays
return(data.frame(x=x, y=y))
}
# Example usage
result=rk4(y0=0, x0=0, h=0.05, n=20)
plot(result$x, result$y, type='b', col='red', main = '4th-order Runge-Kutta Method');grid()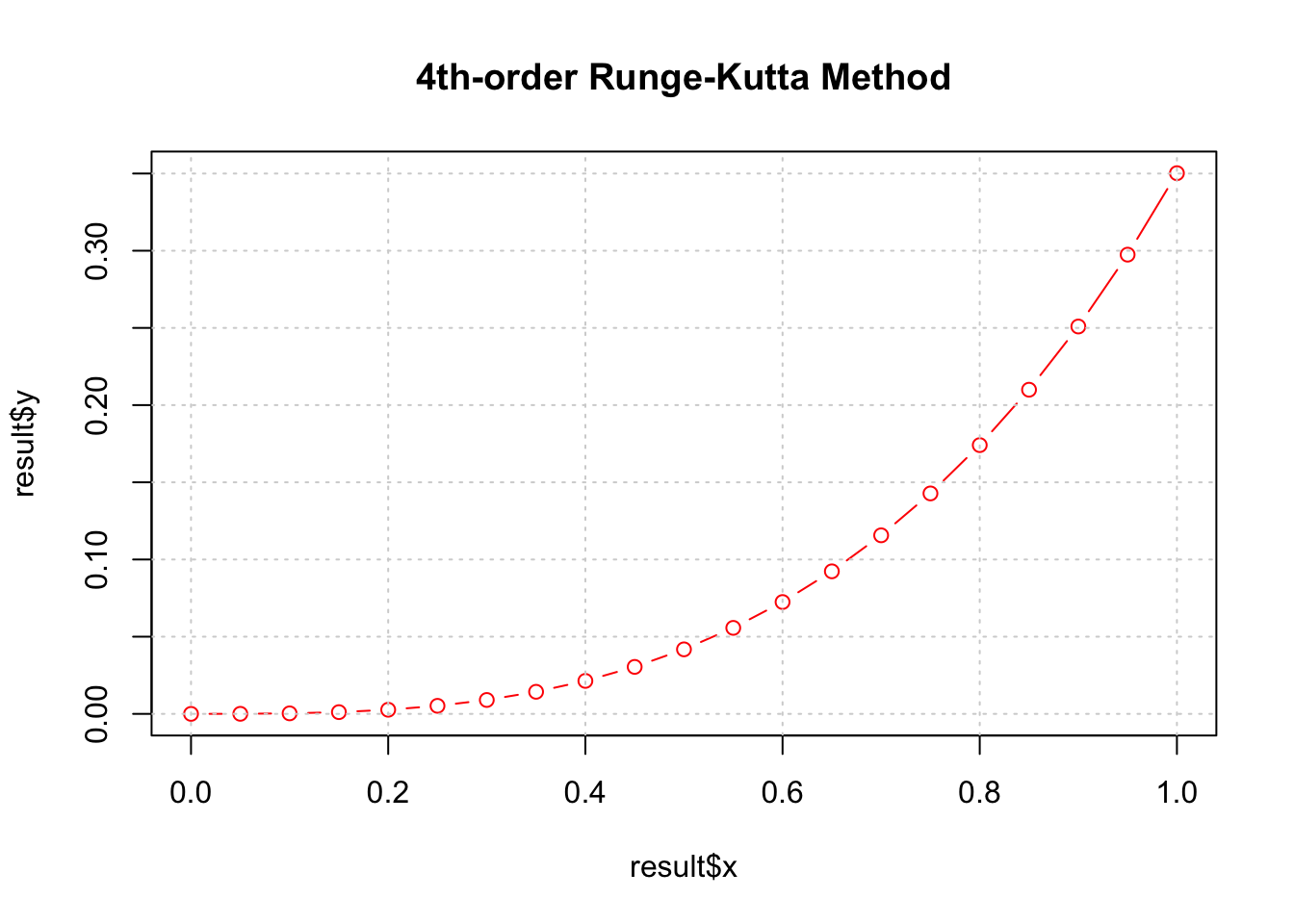
## x y
## 1 0.00 0.000000e+00
## 2 0.05 4.166668e-05
## 3 0.10 3.333350e-04
## 4 0.15 1.125027e-03
## 5 0.20 2.666870e-03
## 6 0.25 5.209303e-03
## 7 0.30 9.003475e-03
## 8 0.35 1.430189e-02
## 9 0.40 2.135939e-02
## 10 0.45 3.043447e-02
## 11 0.50 4.179116e-02
## 12 0.55 5.570135e-02
## 13 0.60 7.244788e-02
## 14 0.65 9.232833e-02
## 15 0.70 1.156599e-01
## 16 0.75 1.427853e-01
## 17 0.80 1.740803e-01
## 18 0.85 2.099633e-01
## 19 0.90 2.509068e-01
## 20 0.95 2.974527e-01
## 21 1.00 3.502320e-012.3 有限元, 有限差分 ,有限体积
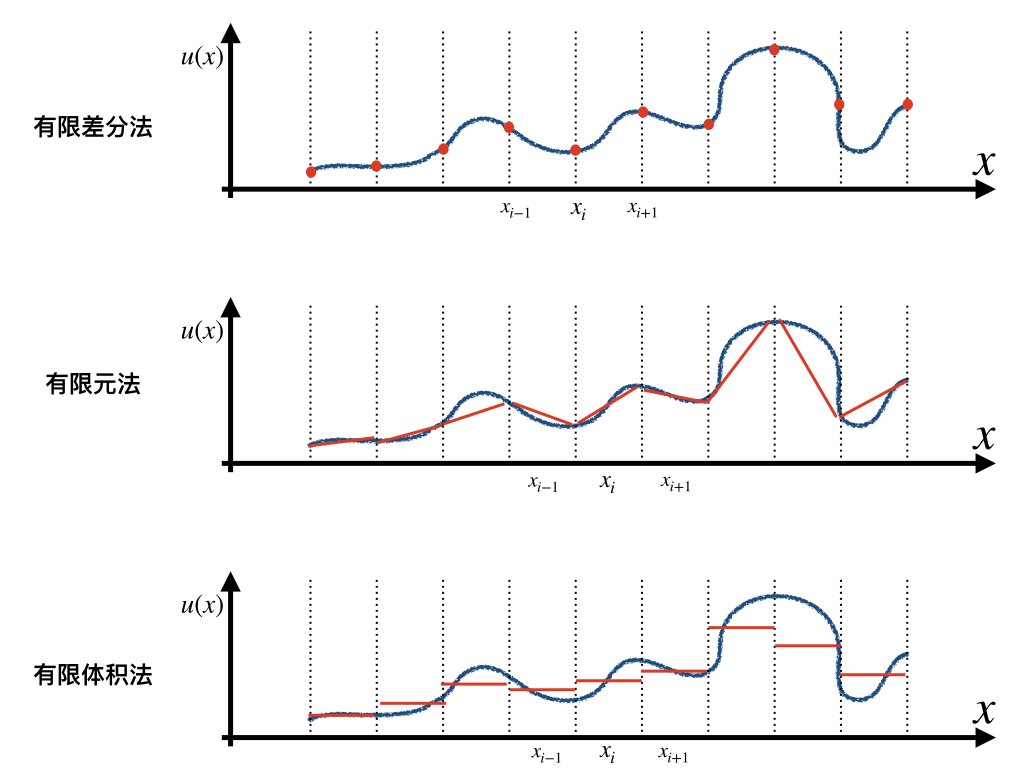
数值方法中主要有有限差分(Finite Difference, FD)、有限元(Finite Element, FE)和有限体积(Finite Volume,FV)法三类。三类方法并无明显优劣之分,但其中各有特点。有限差分法方法简洁,物理意义清晰,编程容易,因而是水文/气象领域应用最多的方法。 有限元法可以保证全局物质/能量守恒,但是无法保证局部守恒;有限体积法弥补了有限元这一缺陷,既可以保证全局守恒,也可以保证局部守恒。
三类方法的数学的意义略有不同:有限差分法计算为空间某一点的值,有限元法计算某一计算单元内的近似拟合曲线,有限体积法作为有限元法的特例,计算该计算单元内的均值。因此对于三种不同方法计算的结果的解读应当略有不同,但实际模型用户层面通常将其视为相同含义。
2.4 CFL条件约束
CFL条件是数值方法求解常/偏微分方程保证其收敛性和稳定性的必要条件,但不是充分条件;以Courant, Fredrichs和Lewy共同命名(cite)。CFL条件即数值方法的时间步长要足够小,方能够保证计算精度,否则结果不收敛或者不稳定。
最简单可以理解为时间推进求解的速度必须大于物理扰动传播的速度,只有这样才能将物理上所有的扰动俘获到。
Definition 2.5 (CFL条件) CFL条件数学表达形式为: 其中即为系统中变量的变化速率。是保持求解系统稳定和收敛的最大值,常见值为0.5。有的系统中,但有的科学问题中。
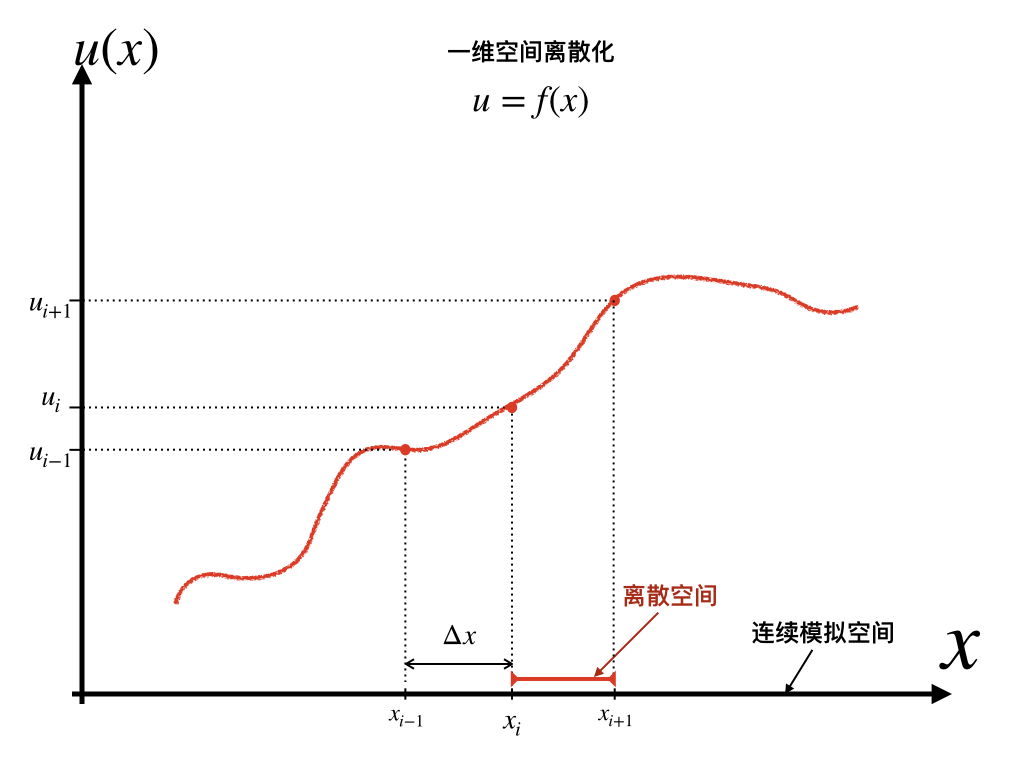
2.5 时空离散化
空间离散化,即分割连续的空间称为空间若干子集的过程,由一维, 二维, 或者三维构成的最小计算单元或质点。
时间离散化即模型时间步长,即。
时间步长和空间分辨率的组合关系,对于数值方法求解的稳定性和收敛性都有显著影响。CFL条件是限制因素。为保证数值方法稳定性,空间分辨率越高,则要求时间分辨率也越高,时间分辨率与空间分辨率的(一次或多次)幂存在正比关系。
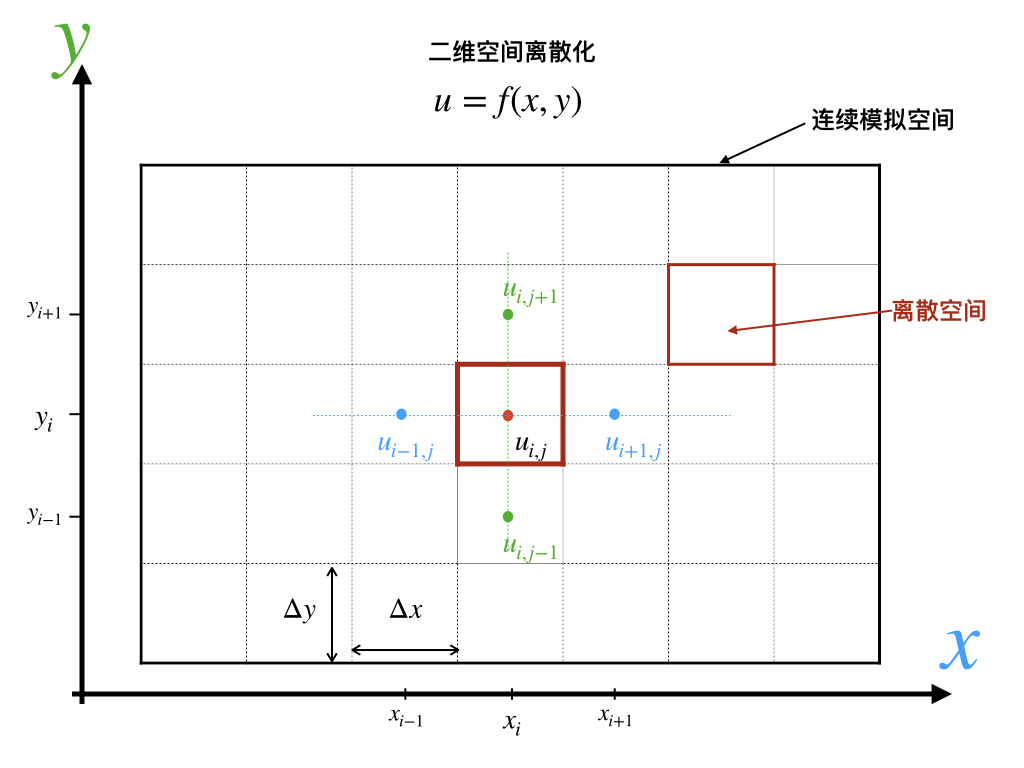
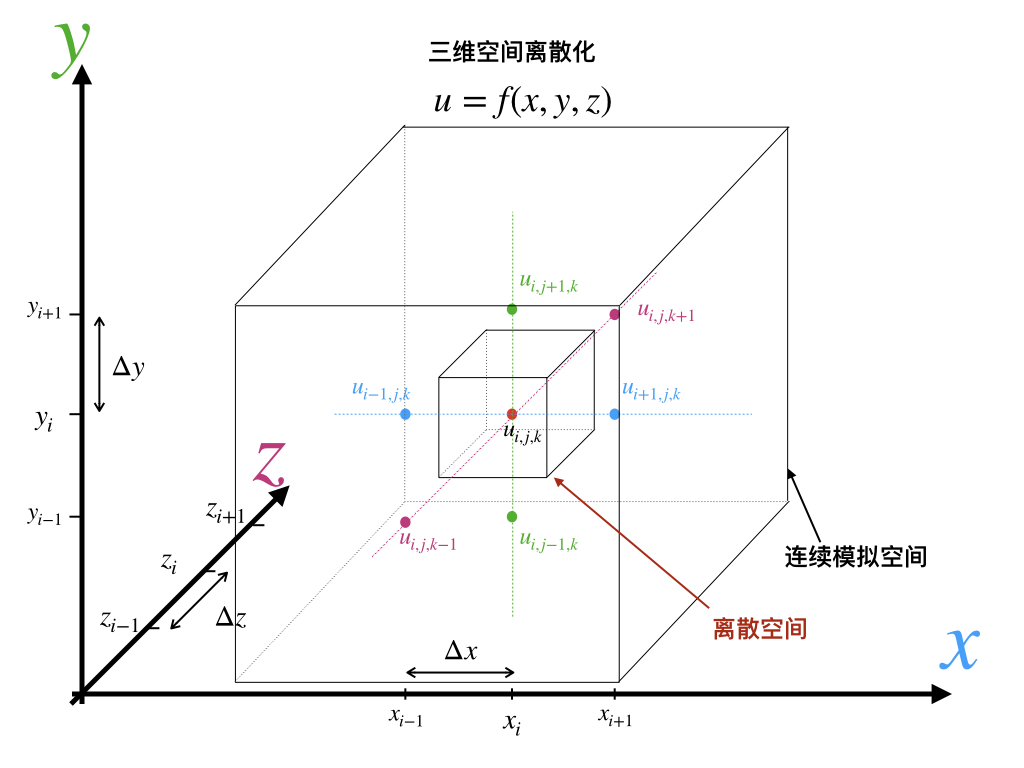
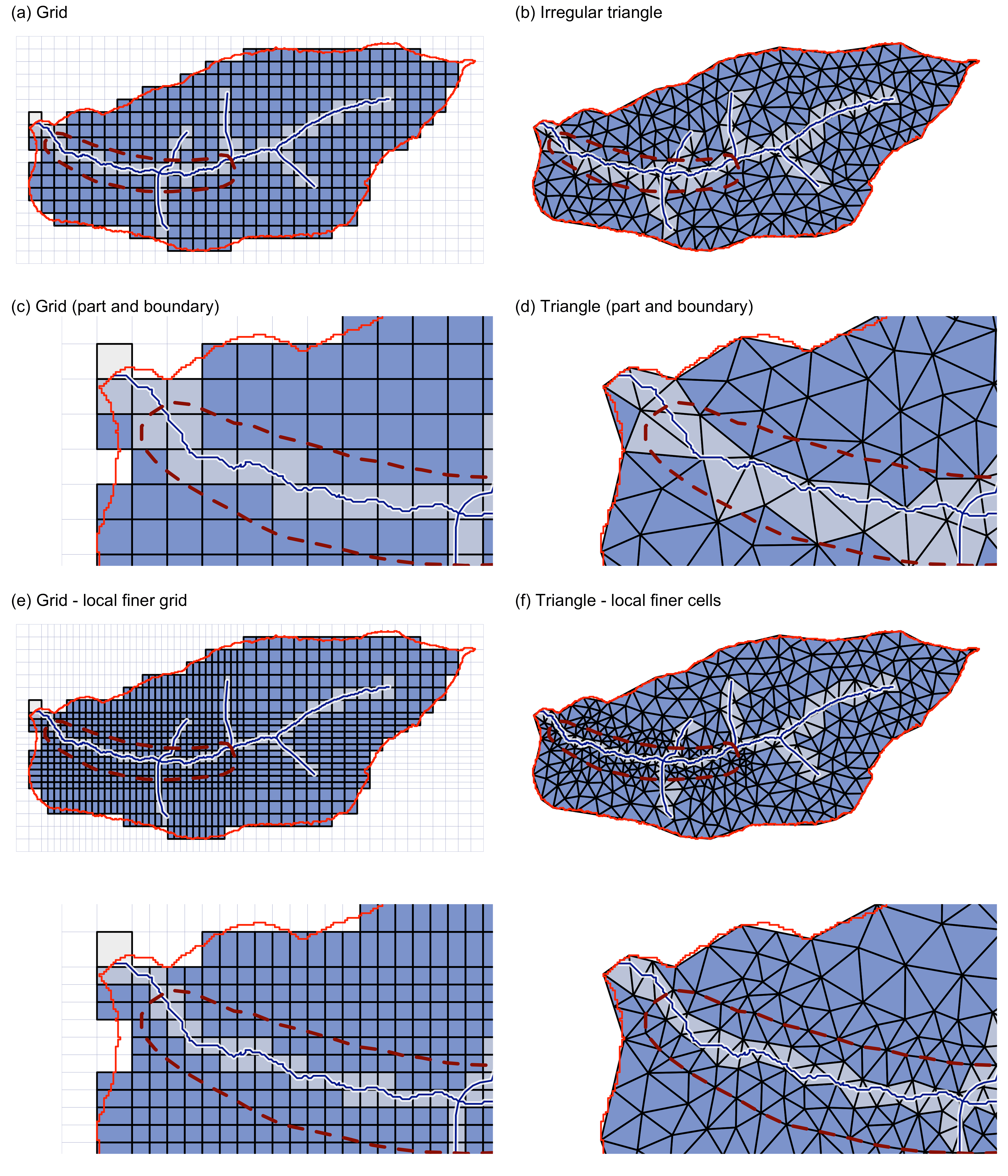
通常的空间离散化分为结构化(Structured)与非结构化(Unstructured)网格。
结构化网格主要是划分为形状和面积相同的计算单元。矩形规则化网格的好处是:求解过程直观易懂,编程实现简单,并且易于并行化;输入和输出数据都直接使用矩阵方式表达;数据制备、处理和可视化都直观且便捷。规则化网格常见矩形,也有正三角形和正六边形的方案。
非结构化网格的优势在于:
- 更好的表现不规则三维地形;
- 更好的表现不规则研究区(流域)的边界,边界条件处理更合理,其边界条件控制也更符合数值理论;
- 计算单元的面积大小灵活可变,可以在保证整体边界条件情况下,对重点地区进行局部加密——亦或相反设置。非结构化网格既可以保证重点区域的高分辨率,在保证可靠的边界条件情况下,不显著增加计算单元数量,保证重点区域模拟精度和计算负担之间的平衡。
非结构化网格的主要缺陷是:
- 计算过程相对复杂,仅支持有限元和有限体积法;
- 数据解读和可视化复杂,需要针对性的数据前处理和后处理软件。
2.6 初始条件
Definition 2.6 (初始条件) 初始条件定义为 其中为问题的初始时刻,为初始时刻包含目标变量值的向量。
数值方法研究中,模拟结果对初始条件具有一定敏感性。但是,初始条件的敏感性问题与描述该系统的控制方程有关。部分问题的初始条件误差,可以通过一定时间的模型预热(Spin-up)消除;但另有一部分问题(例如Lorenz System为代表的混沌系统),初始条件敏感性极高。
2.7 边界条件
数值方法的边界条件通常分为Dirichlet和Neumann两类。
Definition 2.7 (第一类边界条件) Dirichlet边界条件(Dirichlet Boundary Condition, DBC)是常/偏微分方程的第一类边界条件,也称为固定边界条件,其指定了空间某点的固定值,比如在地下水中,Dirichlet边界条件限定固定地下水水头高度。
Definition 2.8 (第二类边界条件) 诺伊曼边界条件(Neumann boundary condition, NBC) 也被称为常/偏微分方程的“第二类边界条件”,其给定空间特定位置上目标变量的一阶导数,在地下水问题中,通常某一点处固定的流量,如注水或者取水量。
作为三维的数值模型,两类边界条件都可以施加在空间任意位置的任意方向上。